I’ve been testing out FeedHub, a tool that organizes and filters your RSS feeds based on topics (“memes,” in FeedHub’s parlance) you express interest in. So far, I’ve found that it helps put things I want to read nearer the top of the list, although it doesn’t do as good a job as my own system of reading certain feeds first.
To get started with FeedHub, you need to set up an account and import an OPML file from your favorite aggregator. The signup procedure was a bit confusing; it wasn’t obvious to me that uploading an OPML file was a required part of the process. Once I figured that out, though, setting up an account was a breeze.
I exported an OPML file from Bloglines (over 120 feeds) and FeedHub started digesting it. The process took several hours; I was warned that it would be time consuming, and it was. When I came back to FeedHub the next day, it had finished its processing and offered me a new RSS feed to which I needed to subscribe to see my filtered feeds. So I added this new feed into Bloglines to monitor it.
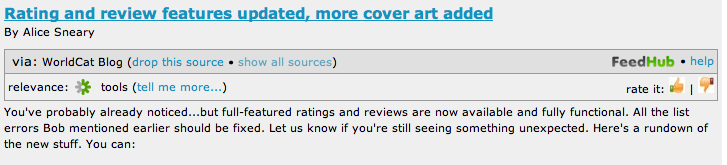
Within the FeedHub feed, each post is reproduced along with an indication of relevance, the memes FeedHub has assigned to the post, and a thumbs up/thumbs down rating icon. Sample (for a recent post in OCLC’s WorldCat blog, “Rating and review features updated, more cover art added‘):
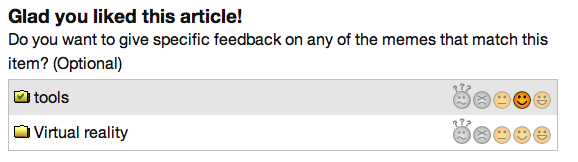
Once you click the appropriate rating thumb, a new window appears in which FeedHub displays its updated relevancy for that article and a series of memes that it has found for that particular post. You can then provide an importance for each meme in your overall reading interests. For example:
This post has been assigned two memes by FeedHub, “tools” and “virtual reality”. (The underlying software, mSpoke, is responsible for assigning memes to topics.) Next to each meme is a series of graphics, reflecting five options for rating that meme: “No opinion,” “No thanks,” “Sometimes,” “Usually,” and “Yes, please.” I’ve previously given the “tools” meme a “usually” rating but haven’t previously expressed an opinion about the Virtual reality meme.
FeedHub can display all the memes it’s gathered to describe my reading interests. Here are the memes I’ve rated as “Yes, please” and “Usually:”
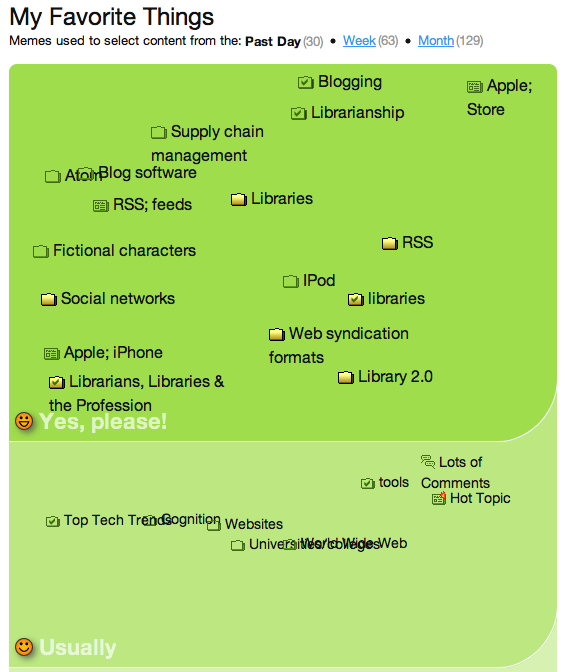
You can drag and drop individual memes from category to category, making it simple to update FeedHub’s settings. You can also add other memes via search interface or add memes that are based on source (i.e., “in popular feeds”, “in TechCrunch”, etc.) or that reflect social web sources — “on the del,icio.us hotlist”, “popular on Digg”, etc.).
So what’s the net effect of FeedHub on my blog reading? It’s been mixed in the week I’ve been testing it. I think I would have been happier had I given it a more homogeneous set of RSS feeds rather than everything — library-related, technology-related, blogs of friends that I follow, news, etc. I think it has a hard time initially figuring out what I actually want to read because the sources are so disparate. I have since pruned my FeedHub subscription list to be just library- and technology-related feeds, which seems to have improved its fidelity. (Or it could be that I’ve simply voted on more items, giving it a better sense of what I actually like.)
FeedHub also notes which blog posts I click through to read at the source site. Since most blog posts are published in their entirety in the RSS feed, I’m not sure how useful this is; I rarely go to the blog’s site to read a post.
Overall, I’m intrigued by the tool and plan to keep using it. However, I’m not yet ready to ditch my entire feed collection as individual posts in favor of FeedHub’s filtered approach.