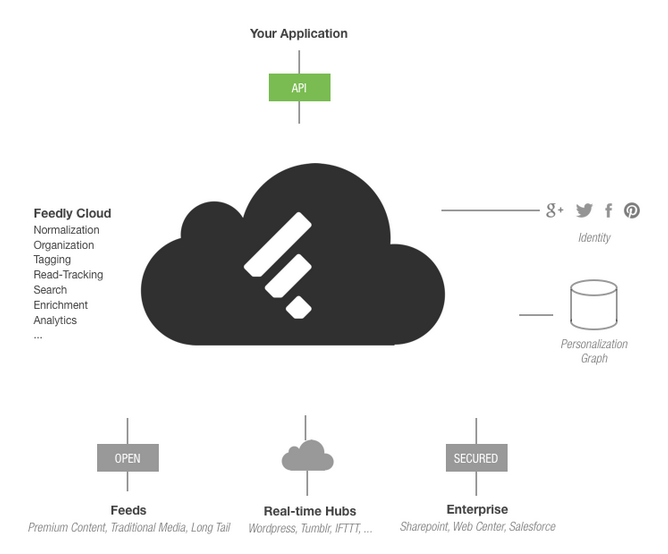
One of the features of Apple’s soon-to-be-released Mavericks operating system is Safari “push notifications.” Similar to what you might be familiar with on an iOS device, these are updates that you can subscribe to from participating websites that will send an alert to Safari when content is updated. Apple’s site says that notifications will be updated even when you are not actively using your computer — meaning that the information you are being sent will always be available to you.
One of the features of Apple’s soon-to-be-released Mavericks operating system is Safari “push notifications.” Similar to what you might be familiar with on an iOS device, these are updates that you can subscribe to from participating websites that will send an alert to Safari when content is updated. Apple’s site says that notifications will be updated even when you are not actively using your computer — meaning that the information you are being sent will always be available to you.
This sounds a wee bit like RSS, doesn’t it? Participating websites can send you updates as they happen, and Safari will track what you have seen. I am assuming that updates will be synchronized across your various devices so that if you read an article on one device, it will be marked as seen on your others (this will probably require an iCloud account).
This is a feature only available to people using Mavericks and Safari 7 (it is not clear if this will be available to earlier versions of the Mac OS or Safari). You also must have an account on Apple’s developer website to access the instructions for setting this up for your website.
It will be interesting to see if Apple manages to replace RSS in its ecosystem with this custom setup, at least for publishers or tech-savvy website managers who can adopt the technology.
A tip of the hat to MacRumors.