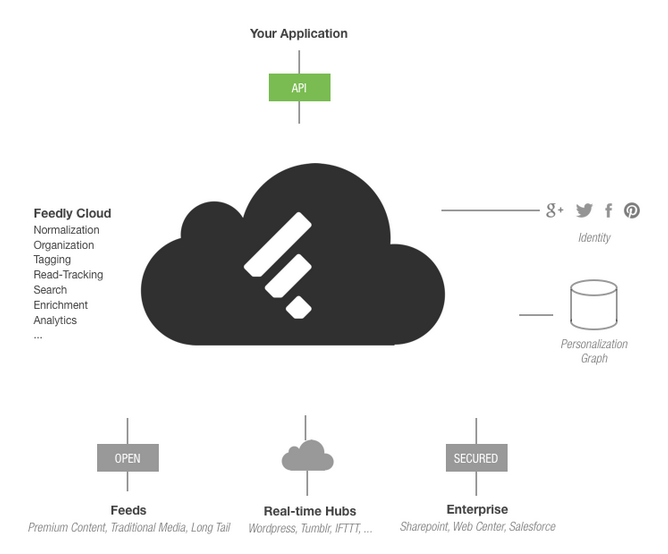
Web Scale Discovery systems (products like Summon, EBSCO Discovery Service, Primo Central, and so on) make their customers love them through their comprehensiveness. These systems index hundreds of millions — some approach a billion items — from scholarly and popular sources, library catalogs, institutional repositories, and more. No matter how esoteric the topic you are looking for, you’re almost certain to find something that’s related. Or close to being related.
With their vast reach, these discovery systems open the door to being almost omniscient alert services. Their coverage is vast, so whenever something new is published on a topic, it is likely to find its way into the discovery index. The challenge, it turns out, is in letting people know when something new is available.
Discovery systems are primarily retrieval systems. They cast a wide net, and sort their results in relevance order. When something new is added to the index and the same search is run, the new items appears somewhere in the list. This is the challenge for any kind of current awareness system (whether it is RSS or email alerts).
If the system simply runs the search again and provides an RSS feed of the 100 most relevant results, for most searches, the new material will be nowhere near the top and the feed will contain exactly what you have already seen. For many topics, the new items won’t even make the relevancy cut and will be excluded.
If the system runs the search and provides an RSS feed in reverse chronological order (newest items on top), the newest items may well be so far down the relevancy ranking that they are, in fact, nearly irrelevant. Try a couple experiments. Do a search in your favorite tool and move down to the 5,000th result. Is it the item you’ve been looking for all your life? Almost certainly not. Do the same search, but resort by publication date (newest first). Is the top result relevant to your query? Again, probably not.
So what is needed is some sort of hybrid, database structure. The items from the original search result set that pass some relevancy threshold need to be saved. Whenever new items are added, these new items are compared to the existing list. If they are more relevant than items in the previously seen list, they are added to an alert, and the list of previously seen and previously alerted items grows. Figuring out which are new (to the user) items is not trivial.
Discovery and RSS are almost inherently at odds with one another. Any ideas on how to build a usable RSS feed to stay apprised of a topic?
 Mashable published an interesting post and infographic about how the “feed” changed the way we consume information. The author notes: “The feed now dominates online content consumption, from the news we read on our mobile devices to the social networks we check constantly throughout the day…” (emphasis mine).
Mashable published an interesting post and infographic about how the “feed” changed the way we consume information. The author notes: “The feed now dominates online content consumption, from the news we read on our mobile devices to the social networks we check constantly throughout the day…” (emphasis mine).